Help Desk
Published over 10 years ago. See the latest and most current information on Help Desk.
Last month’s edition of the help desk looked the issues associated with generating a linear response curve when analysing larger, protein like molecules. Whilst writing the article there was some discussion amongst the help desk about what classified a linear response and as there are several approaches that are used to denote whether a response curve is linear. One of the issues that did arise was the common use of the r2 value to denote whether a curve was linear or not, and also to denote the range over which the assay could effectively be used. It was felt that on some occasions this value was being used when it was really not appropriate to do so and that there are better methods for determining the linearity of a curve, which give a fairer understanding over the range over which a response model can effectively be used.
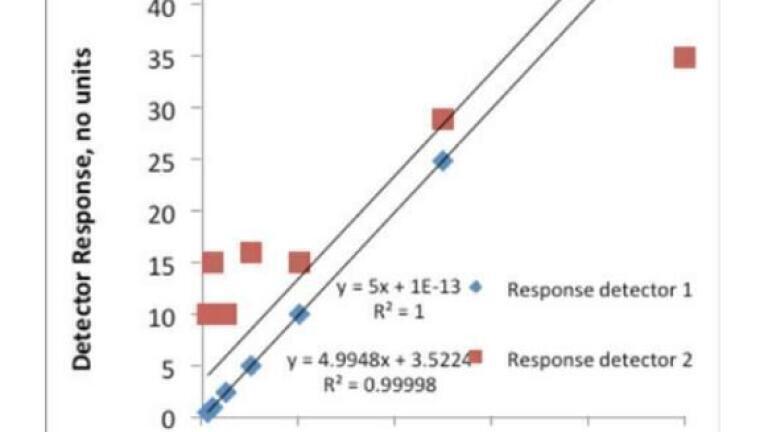
To start the discussion lets first introduce a couple of data sets which have been defined as calibration lines and investigate them to understand why the concept of r2 is not always applicable. Table 1 has both sets of data. In both cases when the r2 value is quoted as 1. This would suggest that there is a linear response of the detector over the concentration range that is given in Table 1. However it is very evident that the response of the second detector is very different to that of the first, and in particular at the lower concentration ranges, and so surely it would be assumed that this detector does not have the same linear range as the first detector? Certainly this is the case but just using the r2 value does not give us that information. Another approach is to monitor the accuracy, that is how far away from the correct response is the detector response. Looking again at Table 1 the higher detection limits offered by detector 2 now become apparent.
This approach which monitors the inaccuracy values or residuals, the difference between the actual data and the predicted data, gives a better indication if the data can be utilised for a linear calibration curve. When discussing the difference between the proposed model and the actual data the response or ‘y’ values are the components that are being considered. The accuracy values are quoted as a percentage whereas the residual values are the absolute differences between the measured value and the predicted data using.
To get a better understanding of why this is the case it is necessary to understand the mathematics behind the calculations. The correlation coefficient r, is given by;
Thus, r, is a measure of the relationship between x and y and does give an indication of the average distance that the measured and predicted values differ by, however this number, as is demonstrated in Table 1, is very much loaded. Thus in a situation where the calibration points are clustered tightly around the calibration line this will result in an r2 value approaching 1. However, an r2 value does not necessarily mean that the calibration line is linear, or if indeed the data fits the proposed calibration model.
The use of residuals does give a better approach to monitoring the applicability of a particular curve to modelling the data. In most cases the simplest model is always preferred, and this will be a linear relationship between the experimental varied parameter (i.e. compound concentration) and the observed variable (i.e. detector response). In order to determine the residual, it is first necessary to perform a linear regression to calculate the gradient and intercept values for the calibration curve. It is possible to also calculate the best fit curve based on a quadratic, cubic or even quartic function, however the mathematics behind can become a little awkward to understand. Most commercial software will calculate the gradient and also the intercept and will also allow for a degree of weighting associated with the individual data points, this will in general be inversely proportional to the size of the experimental parameter, the X-value.
Plotting the residuals for datasets where there is a quantitative linear relationship between the parameter being varied and the response will result in a random response, whereas if the linearity starts to drop off then the residual will start to become bigger as linearity is lost. Data sets which cover a wide range and where the calibration model is not weighted will often have residuals which grow at the lower concentrations. It is therefore always recommended to add a weighting to calibration curve that covers 3 orders of magnitude or larger to offset this effect.
Other statistical approaches can be applied to the analysis of the data to ensure that there the mathematical model used is appropriate for the experimental data. Thus if the experimental data better fits a quadratic curve rather than a linear response curve, the use of ANOVA (analysis of variance) will highlight this as the residual curve will not be random but will have some structure and the ANOVA will demonstrate that there is a significant lack of fit.
In terms of ensuring that the proposed model is adequate, it is also necessary to have enough data points to ensure that the calibration model is valid. In general the default for this has been six data points, and certainly the regulators would support this value. In terms of determining the values to choose, then thought must be given to what the calibration model is being used for, and the likely data that will be produced. Thus, a calibration model may be valid over several orders of magnitude, however if the bulk of the data to be analysed exists in a smaller region, then it makes sense that this is the focus of the calibration set.
As technology progresses and software gets ever easier to use, it can be all too easy to take data that is generated and not really understand what this data actually means, and then based on this start to draw wrong conclusions. The area of statistical analysis is one such discipline, where the simplification of the of the analytical process means that it is all too easy to generate a number without a real understanding of what that number actually means.
General Reading
Analytical Methods Committee, Analyst 1988 (113) 1469
Analytical Methods Committee, Analyst 1994 (119) 2363
www.data\amc\amctb\tb3 linearity